Book - fundamentals of data engineering
Big 10 landmarks
- There are phases of data maturity
- Data engineers serve to create data for ML
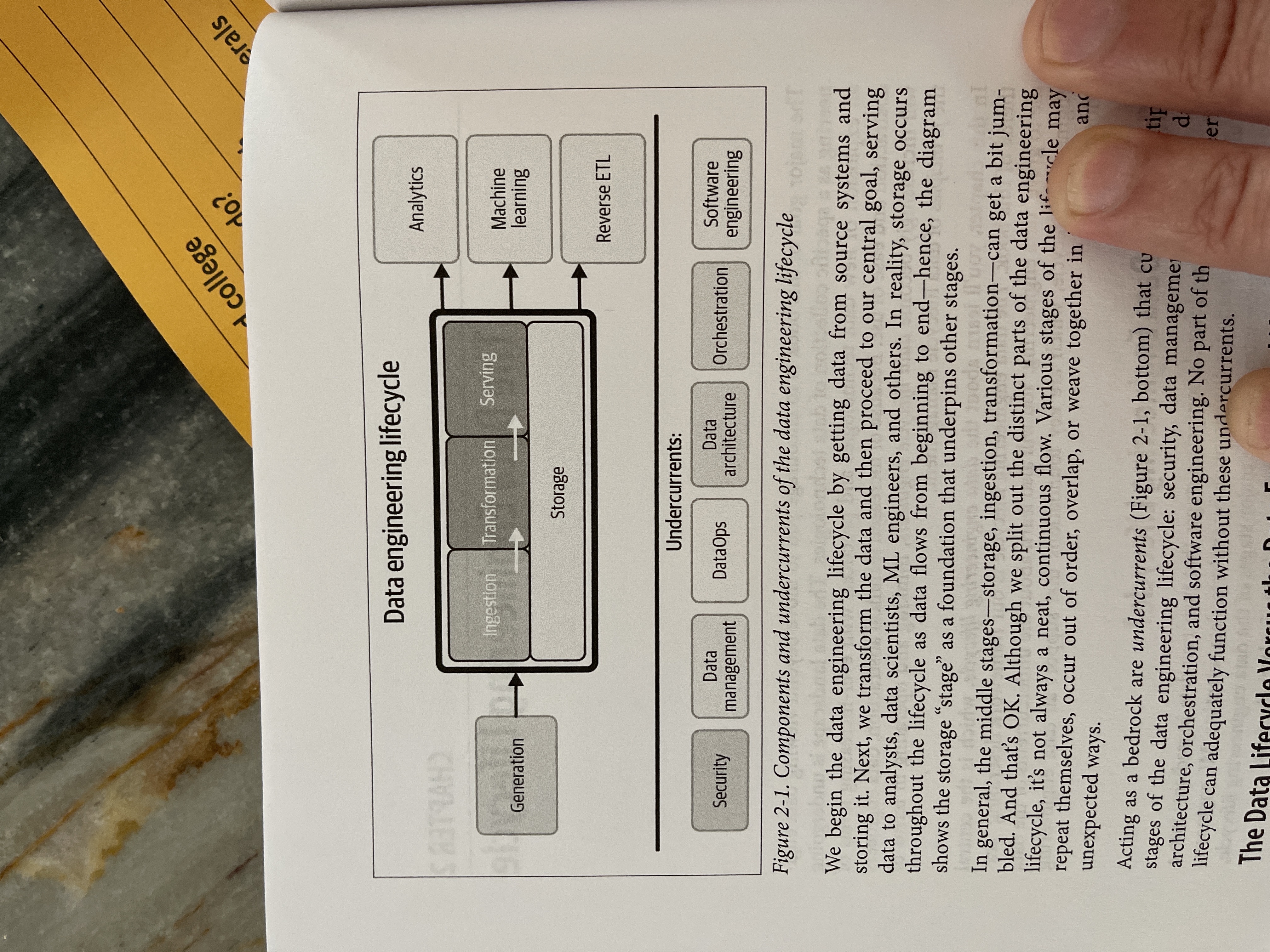
- their knowledge schema is a "data engineering lifecycle"
- The lifecycle has a set of undercurrents
- Ideally you plug components together, only developing specifically where there is differentiated business value
Gaps
At this point I would say I'm an experienced data engineer. So reading this type of book is more about helping me find and plug gaps.
- Data mesh
- Security and governance
- Data catalog (p222) across all storage
Notes
Gives references to related pieces of work at the end of each chapter ^6615aa
Page 36k Data maturity is the progression toward higher data utilization, capabilities, and integration across the organization, but data maturity does not simply depend on the age or revenue of a company. An early-stage startup can have greater data maturity than a 100-year-old company with annual revenues in the billions. What matters is the way data is leveraged as a competitive advantage.
Page 22 talks about type a data engineers and type B data engineers. Recently I have definitely become a type B data engineer, because of the challenges we are facing.
Page 25 talks about decisions made during the implementation process .
Page 38 and 42 evaluation checklist for source systems and storage systems ^evaluation-checklists
Page 43 Blog draft streaming vs batch
Page 44 push vs pull
Page 55 for example data scanning tools can generate wiki pages with links to relevant data objects ^tools-that-generate-wiki-pages
Page 60 data observability driven development DODD is closely related to data lineage.
Page 61 Dataops maps the best practices of agile methodology, DevOps, and statistical process control SPC to data
Page 66 this doesn't imply that a data engineer is a data architect, as these are typically separate roles
EA delivers value by presenting business and IT leaders with signature-ready recommendations for adjusting policies and projects to achieve targeted business outcomes that capitalize on relevant business disruptions. ^signature-ready
an architect’s job is to develop deep knowledge of the baseline architecture (current state), develop a target architecture, and map out a sequencing plan to determine priorities and the order of architecture changes. ^move-towards-a-target-architecture
Transform processes can populate the data mart with joined and aggregated data to improve performance for live queries. ^data-mart-makes-queryable-data
Page k184: The philosophy of “batch as a special case of streaming” is now more pervasive. Various frameworks such as Flink and Spark have adopted a similar approach. ^batch-special-case-of-streaming
Page k189 data mesh attempts to invert the challenges of centralized data architecture, taking the concepts of domain-driven design (commonly used in software architectures) and applying them to data architecture. ^data-mesh
Page k210: Immutable technologies might be components that underpin the cloud or languages and paradigms that have stood the test of time. In the cloud, examples of immutable technologies are object storage, networking, servers, and security. ^bb80d0
Page K213 in the last decade, many CTOs have come to view their decisions around technology hosting as having existential significance for their organizations. If they move too slowly, they risk being left behind by their more agile competition; on the other hand, a poorly planned cloud migration could lead to technological failure and catastrophic costs.
Page k213 In the last decade, many CTOs have come to view their decisions around technology hosting as having existential significance for their organizations. If they move too slowly, they risk being left behind by their more agile competition; on the other hand, a poorly planned cloud migration could lead to technological failure and catastrophic costs.
Page k223 the company may like AWS because it has several best-in-class services (e.g., AWS Lambda) and enjoys huge mindshare, making it relatively easy to hire AWS-proficient engineers.
Page k226 They make a somewhat more subtle argument that companies should expend significant resources to control cloud spending and should consider repatriation as a possible option.
Page k229 we suggest investing in building and customizing when doing so will provide a competitive advantage for your business.
Page k230 Whenever possible, lean toward type A behavior; avoid undifferentiated heavy lifting and embrace abstraction.
Page 145 We view data modularity as a more powerful paradigm than monolithic data engineering.
Page k246 Things are moving so fast in the data space right now. Committing to a monolith reduces flexibility and reversible decisions.
Page 335k what is the opposite of ACID?:: BASE
Page 211. What is the central idea behind the data lake house concept?:: Update management for object storage.
Page 386k good engineering must consider link not tracked by actively seeking to understand its characteristics and watching for major changes.
Fully managed systems are generally far more robust and scalable than systems you have to babysit. ^fully-managed-systems-robust-scalable
Page 395k Business processes have long imposed artificial bounds on data by cutting discrete batches. Keep in mind the true unboundedness of your data; streaming ingestion systems are simply a tool for preserving the unbounded nature of data so that subsequent steps in the lifecycle can also process it continuously. ^artificial-bounds-cutting-discrete-batches
Page 442k be sure to track the various aspects of time—event creation, ingestion, process, and processing times.
Page 443 Data is entropic; it often changes in unexpected ways without warning. One of the inherent differences between DevOps and DataOps is that we expect software regressions only when we deploy changes, while data often presents regressions independently because of events outside our control.
Page 444 link not tracked is a new realm, but one that is likely to grow dramatically in the next five years.
Page 446 As we’ve emphasized, we’re also in the midst of a sea change, moving from batch toward streaming data pipelines.
Page 454 You won’t directly work with a query optimizer, but understanding some of its functionality will help you write more performant queries.